
lunes, 3 de junio de 2019

miércoles, 29 de mayo de 2019


miércoles, 8 de mayo de 2019
asignacion
DEFINICIÓN DEASIGNACIÓN
El término asignación proviene del latín assignatio. Se trata del acto y el resultado de asignar: indicar, establecer u otorgar aquello que corresponde. El concepto puede emplearse con referencia al monto estipulado como salario o por otra clase de percepción.
Por ejemplo: “El gobierno anunció un incremento de la Asignación Universal por Hijo”, “El Estado se comprometió a pagar una asignación familiar para ayudar a satisfacer las necesidades básicas insatisfechas de aquellas personas que no tienen empleo”, “La cámara empresaria acordó una asignación no remunerativa de 6500 pesos”.
En Argentina, desde 2009, existe la Asignación Universal por Hijo para Protección Social. Esta asignación se paga a los individuos desempleados, que tienen un trabajo informal (en negro) o que reciben un ingreso inferior al salario mínimo fijado por la ley, abonándose un beneficio por cada uno de sus hijos que tengan menos de 18 años. Si los hijos son discapacitados, no existe límite de edad.
almacenamiento,direccionamiento,reprecentacion de memoria
Almacenamiento, direccionamiento y representación en memoria.
Almacenamiento
La computadora posee determinada cantidad de almacenamiento interno denominado memoria principal, memoria RAM o memoria volátil. Esta memoria se activa al encender la computadora y se desactiva al apagarla. Para que un programa se ejecute, debe cargarse en la memoria principal, así como los datos necesarios. Como es más costosa, es un recurso escaso donde sólo se almacenan los datos que se requieren de inmediato, y los demás se relegan a los dispositivos de almacenamiento externo, donde la capacidad de almacenamiento es mayor, pero también el tiempo de recuperación. Por otra parte, el costo del almacenamiento externo es más bajo.
Direccionamiento
La memoria principal de la computadora se divide en pequeñas unidades de tamaño uniforme denominadas palabras, que tienen una dirección única.
Cada una de éstas palabras es capaz de almacenar una unidad de información (como, por ejemplo, resultados numéricos), y determina el número más grande y el más pequeño que puede almacenar.
El tamaño de la palabra depende de la computadora, pero siempre se especifica en múltiplos de 8 bits. Así, existen computadoras con tamaños de palabra de 8, 16, 32 y 64 bits.
Cada palabra de la memoria principal tiene una dirección fija que va de cero hasta el número total de palabras - 1. Las direcciones de memoria sirven para identificar cada palabra individualmente, de tal manera que pueda accederse al dato contenido en ella. A fin de simplificar su comprensión, las memorias se consideran como una hilera de palabras.
Por ejemplo, suponiendo que la memoria principal de una computadora tiene un tamaño de palabra de 8 bits, la cinta de color amarillo que se muestra enseguida podría representar las tres primeras palabras:
Dirección
P a l a b r a
Valor en decimal
0000
0
1
0
0
1
0
1
1
75
0001
0
1
0
0
0
0
0
1
65
0002
0
0
1
1
0
0
1
0
50
Representación en memoria
La representación en memoria de los caracteres no reviste mayor complicación, debido a que los códigos utilizados, como el ASCII (American Standard Code for Information Interchange), les asignan valores enteros positivos.
En el caso de los datos numéricos hay que considerar la distinción entre números negativos y positivos, y la que hay entre números de punto flotante y enteros.
Los signos se manejan normalmente mediante el bit más significativo de la palabra (el situado a la extrema izquierda), y se le denomina bit de signo. Cuando el bit de signo almacena un cero, el número se considera positivo; cuando almacena un uno el número es negativo. Es por esto que, si el tamaño de la palabra es de m bits, quedan m-1 bits para representar la magnitud del número almacenado.
Los números de punto flotante se manejan en formato logarítmico, con un número fijo de bits para la base y otro para la mantisa. El estándar para los números de punto flotante lo fija el IEEE.
Debido al formato logarítmico, los cálculos que se hacen con tipos de punto flotante no son tan precisos como los que se hacen con tipos enteros
La computadora posee determinada cantidad de almacenamiento interno denominado memoria principal, memoria RAM o memoria volátil. Esta memoria se activa al encender la computadora y se desactiva al apagarla. Para que un programa se ejecute, debe cargarse en la memoria principal, así como los datos necesarios. Como es más costosa, es un recurso escaso donde sólo se almacenan los datos que se requieren de inmediato, y los demás se relegan a los dispositivos de almacenamiento externo, donde la capacidad de almacenamiento es mayor, pero también el tiempo de recuperación. Por otra parte, el costo del almacenamiento externo es más bajo.
Direccionamiento
La memoria principal de la computadora se divide en pequeñas unidades de tamaño uniforme denominadas palabras, que tienen una dirección única.
Cada una de éstas palabras es capaz de almacenar una unidad de información (como, por ejemplo, resultados numéricos), y determina el número más grande y el más pequeño que puede almacenar.
El tamaño de la palabra depende de la computadora, pero siempre se especifica en múltiplos de 8 bits. Así, existen computadoras con tamaños de palabra de 8, 16, 32 y 64 bits.
Cada palabra de la memoria principal tiene una dirección fija que va de cero hasta el número total de palabras - 1. Las direcciones de memoria sirven para identificar cada palabra individualmente, de tal manera que pueda accederse al dato contenido en ella. A fin de simplificar su comprensión, las memorias se consideran como una hilera de palabras.
Por ejemplo, suponiendo que la memoria principal de una computadora tiene un tamaño de palabra de 8 bits, la cinta de color amarillo que se muestra enseguida podría representar las tres primeras palabras:
Dirección
P a l a b r a
Valor en decimal
0000
0
1
0
0
1
0
1
1
75
0001
0
1
0
0
0
0
0
1
65
0002
0
0
1
1
0
0
1
0
50
Representación en memoria
La representación en memoria de los caracteres no reviste mayor complicación, debido a que los códigos utilizados, como el ASCII (American Standard Code for Information Interchange), les asignan valores enteros positivos.
En el caso de los datos numéricos hay que considerar la distinción entre números negativos y positivos, y la que hay entre números de punto flotante y enteros.
Los signos se manejan normalmente mediante el bit más significativo de la palabra (el situado a la extrema izquierda), y se le denomina bit de signo. Cuando el bit de signo almacena un cero, el número se considera positivo; cuando almacena un uno el número es negativo. Es por esto que, si el tamaño de la palabra es de m bits, quedan m-1 bits para representar la magnitud del número almacenado.
Los números de punto flotante se manejan en formato logarítmico, con un número fijo de bits para la base y otro para la mantisa. El estándar para los números de punto flotante lo fija el IEEE.
Debido al formato logarítmico, los cálculos que se hacen con tipos de punto flotante no son tan precisos como los que se hacen con tipos enteros
identificadores
| ||||
Identificadores. Un identificador es un conjunto de caracteres alfanuméricos de cualquier longitud que sirve para identificar las entidades del programa (clases, funciones, variables, tipos compuestos) Los identificadores pueden ser combinaciones de letras y números. Cada lenguaje tiene sus propias reglas que definen como pueden estar construidos. Cuando un identificador se asocia a una entidad concreta, entonces es el "nombre" de dicha entidad, y en adelante la representa en el programa. Nombrar las entidades hace posible referirse a las mismas, lo cual es esencial para cualquier tipo de procesamiento simbólico.
Sumario
[ocultar]Identificadores en lenguajes informáticos
En los lenguajes informáticos, los identificadores son elementos textuales (también llamados símbolos) que nombran entidades del lenguaje. Algunas de las de entidades que un identificador puede denotar son las variables, las constantes, los tipos de dato, las etiquetas, las subrutinas (procedimientos y funciones) y los paquetes.
En muchos lenguajes algunas secuencias tienen la forma léxica de un identificador pero son conocidos como palabras clave (o palabras reservadas). Lo habitual es que si un identificador se corresponde con una palabra clave o reservada, éste ya no pueda utilizarse para referirse a otro tipo de entidades como variables o constantes (en unos pocos lenguajes, como PL/1, esta distinción no está del todo clara).
Los lenguajes informáticos normalmente ponen restricciones en qué caracteres pueden aparecer en un identificador. Por ejemplo, en las primeras versiones de C y C++, los identificadores están restringidos para que sean una secuencia de una o más letras ASCII, dígitos numéricos (que en ningún caso deben aparecer como primer carácter) y barras bajas. Las versiones posteriores de estos lenguajes, así como otros muchos más lenguajes modernos soportan casi todos los caracteres Unicode en un identificador. Una restricción común es que no está permitido el uso de espacios en blanco ni operadores del lenguaje.
En lenguajes de programación compilados, los identificadores generalmente son entidades en tiempo de compilación, es decir, en tiempo de ejecución el programa compilado contiene referencias a direcciones de memoria y offsets más que identificadores textuales (estas direcciones de memoria u offsets, han sido asignadas por el compilador a cada identificador).
En lenguajes interpretados los identificadores están frecuentemente en tiempo de ejecución, a veces incluso como objetos de primera clase que pueden ser manipulados y evaluados libremente. En Lisp, éstos se llaman símbolos.
Los compiladores e intérpretes normalmente no asignan ningún significado semántico a un identificador basado en la secuencia de caracteres actual. Sin embargo, hay excepciones. Por ejemplo:
En muchos lenguajes algunas secuencias tienen la forma léxica de un identificador pero son conocidos como palabras clave (o palabras reservadas). Lo habitual es que si un identificador se corresponde con una palabra clave o reservada, éste ya no pueda utilizarse para referirse a otro tipo de entidades como variables o constantes (en unos pocos lenguajes, como PL/1, esta distinción no está del todo clara).
Los lenguajes informáticos normalmente ponen restricciones en qué caracteres pueden aparecer en un identificador. Por ejemplo, en las primeras versiones de C y C++, los identificadores están restringidos para que sean una secuencia de una o más letras ASCII, dígitos numéricos (que en ningún caso deben aparecer como primer carácter) y barras bajas. Las versiones posteriores de estos lenguajes, así como otros muchos más lenguajes modernos soportan casi todos los caracteres Unicode en un identificador. Una restricción común es que no está permitido el uso de espacios en blanco ni operadores del lenguaje.
En lenguajes de programación compilados, los identificadores generalmente son entidades en tiempo de compilación, es decir, en tiempo de ejecución el programa compilado contiene referencias a direcciones de memoria y offsets más que identificadores textuales (estas direcciones de memoria u offsets, han sido asignadas por el compilador a cada identificador).
En lenguajes interpretados los identificadores están frecuentemente en tiempo de ejecución, a veces incluso como objetos de primera clase que pueden ser manipulados y evaluados libremente. En Lisp, éstos se llaman símbolos.
Los compiladores e intérpretes normalmente no asignan ningún significado semántico a un identificador basado en la secuencia de caracteres actual. Sin embargo, hay excepciones. Por ejemplo:
- En Perl una variable se indica utilizando un prefijo llamado sigil, que especifica aspectos de cómo se interpreta la variable en las expresiones.
- En Ruby una variable se considera automáticamente como inmutable si su identificador empieza con una letra mayúscula.
- En Fortran, la primera letra de una variable indica si por defecto es creada como entero o como flotante.
Identificadores C++
Los identificadores C++ pueden contener las letras a a z y A a Z, el guión bajo "_" ("Underscore") y los dígitos 0 a 9.
Caracteres permitidos
a b c d e f g h i j k l m n o p q r s t u v w x y z
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Dígitos permitidos
0 1 2 3 4 5 6 7 8 9
Solo hay dos restricciones en cuanto a la composición:
- El primer carácter debe ser una letra o el guión bajo. El Estándar establece que los identificadores comenzando con guión bajo y mayúscula no deben ser utilizados. Este tipo de nombres se reserva para los compiladores y las Librerías Estándar. Tampoco se permite la utilización de nombres que contengan dos guiones bajos seguidos.
- El estándar ANSI establece que como mínimo serán significativos los 31 primeros caracteres, aunque pueden ser más, según la implementación. Es decir, para que un compilador se adhiera al estándar ANSI, debe considerar como significativos, al menos, los 31 primeros caracteres.
Los identificadores distinguen mayúsculas y minúsculas, así que Sum, sum y suM son distintos para el compilador. Sin embargo, C++Builderofrece la opción de suspender la sensibilidad a mayúsculas / minúsculas, lo que permite la compatibilidad con lenguajes insensibles a esta cuestión, en este caso, las variables globales Sum, sum y suM serían consideradas idénticas, aunque podría resultar un mensaje de aviso "Duplicate symbol" durante el enlazado.
Con los identificadores del tipo pascal hay una excepción a esta regla, ya que son convertidos siempre a mayúsculas con vistas al enlazado.
Los identificadores globales importados desde otros módulos siguen las mismas reglas que los identificadores normales.
Aunque los nombres de los identificadores pueden ser arbitrarios (dentro de las reglas señaladas), se produce un error si se utiliza el mismo identificador dentro del mismo ámbito compartiendo el mismo espacio de nombres. Los nombres duplicados son legales en diferentes espacios de nombres con independencia de las reglas de ámbito.
Un identificador no puede coincidir con una palabra clave o con el de ninguna función de biblioteca.
Con los identificadores del tipo pascal hay una excepción a esta regla, ya que son convertidos siempre a mayúsculas con vistas al enlazado.
Los identificadores globales importados desde otros módulos siguen las mismas reglas que los identificadores normales.
Aunque los nombres de los identificadores pueden ser arbitrarios (dentro de las reglas señaladas), se produce un error si se utiliza el mismo identificador dentro del mismo ámbito compartiendo el mismo espacio de nombres. Los nombres duplicados son legales en diferentes espacios de nombres con independencia de las reglas de ámbito.
Un identificador no puede coincidir con una palabra clave o con el de ninguna función de biblioteca.
Tipos de identificadores
El estándar ANSI distingue dos tipos de identificadores:
- Identificadores internos; los nombres de macros de preprocesado y todas las que no tengan enlazado externo. El estándar establece que serán significativos, al menos, los primeros 31 caracteres.
- Identificadores externos; los que corresponden a elementos que tengan enlazado externo. En este caso el estándar es más permisivo. Se acepta que el compilador identifique solo seis caracteres significativos y pueda ignorar la distinción mayúsculas/minúsculas

tipos de datos
Tipos de datos
Un tipo de datos es la propiedad de un valor que determina su dominio (qué valores puede tomar), qué operaciones se le pueden aplicar y cómo es representado internamente por el computador.
Todos los valores que aparecen en un programa tienen un tipo.
A continuación revisaremos los tipos de datos elementales de Python. Además de éstos, existen muchos otros, y más adelante aprenderemos a crear nuestros propios tipos de datos.
Números enteros
El tipo int (del inglés integer, que significa «entero») permite representar números enteros.
Los valores que puede tomar un int son todos los números enteros: ... -3, -2, -1, 0, 1, 2, 3, ...
Los números enteros literales se escriben con un signo opcional seguido por una secuencia de dígitos:

martes, 30 de abril de 2019
Estructura selectiva o de selección
3.2 Estructura básica de un programa.

jueves, 11 de abril de 2019




miércoles, 10 de abril de 2019


martes, 2 de abril de 2019






lunes, 25 de marzo de 2019



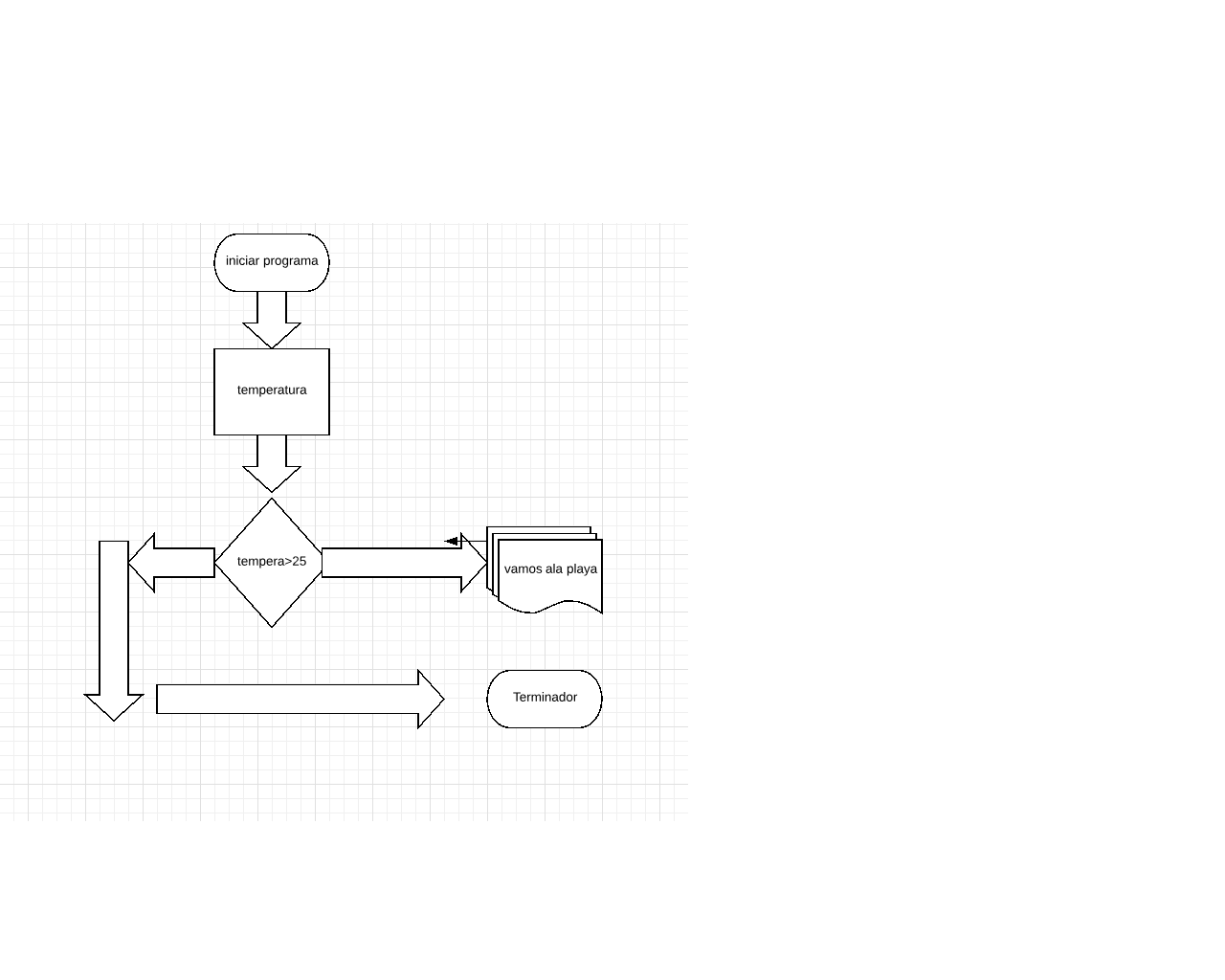
miércoles, 13 de marzo de 2019
algoritmos secuenciales
Semana 2.Evidencia de aprendizaje.Tema: Algoritmos 1.1Instrucciones.Paso 1.- Lee la etapa 1 de tu libro de texto TIC 1.Paso 2.- Revisa los videos de la etapa 1.Paso 3.- Analiza los ejemplos A y B de la etapa 1 de tu guía de aprendizaje.Paso 4.- Elabora los siguientes algoritmos secuenciales:►Determina el perímetro de un rectángulo.►Convierte una cantidad cualquiera de pesos a dólares.►Determina el área de un pentágono. ►Determina la velocidad final de un auto si su velocidad inicial es 0 km/h y su aceleración es 0.8 m/s2; y el tiempo transcurrido es de 30 segundos.Paso 5.- Analiza ejemplos C y D de la etapa 1.Paso 6.- Elabora los siguientes algoritmos condicionales: ►Determina si una persona tiene derecho a •Identifica el inicio y el final.•Enumera cada uno de los pasos•Describe los pasos, sin ambigüedad, siendo preciso y veras en la solución del problema.•Utiliza lenguaje sencillo en la descripción. Algoritmos Secuenciales.►Determina el perímetro de un rectángulo.►Convierte una cantidad cualquiera de pesos a dólares.►Determina el área de un pentágono. ►Determina la velocidad final de un auto si su velocidad inicial es 0 km/h y su aceleración es 0.8 m/s2; y el tiempo transcurrido es de 30 segundos.►Determina el perímetro de un rectángulo.1.- Inicio.2.- Variables; Perímetro, L1=10 cm, L2=20 cm, L3=10 cm, L4=10 cm.3.- Perímetro es igual a L1+L2+L3+L4.4.- P=10+20+10+205.- P=60 cm.6.- Fin.►Convierte una cantidad cualquiera de pesos a dólares.1.-Inicio.2.-Determinar variables. x=1000 pesos; y= ¿?dólares. 3.- Un dólar=13.49.4.- y= x/13.495.- y= 74.12 dólares 6.- 1000 pesos son 74.12 dólares.7.- Fin.►Determina el área de un pentágono. 1.- Inicio.2.- Variables; Área= ¿?, Perímetro=10, Apotema=8.3.- Área es igual a 10*8/24.- Área=405.- Fin►Determina la velocidad final de un auto si su velocidad inicial es 0 km/h y su aceleración es 0.8 m/s2; y el tiempo transcurrido es de 30 segundos.
Estructura Selectiva
La estructura lógicas selectivas se encuentran en la solución algorítmica de casi todo tipo de problemas. Las utilizamos cuando en el desarrollo de la solución de un problema debemos tomar una decisión, para establecer un proceso o señalar un camino alternativo a seguir.Esta toma de decisión (expresada con un rombo) se basa en la evaluación de una o más condiciones que nos señalarán como alternativa o consecuencia, la rama a seguir.Hay situaciones en las que la toma de decisiones se realiza en cascada. Es decir se toma una decisión, se marca la rama correspondiente a seguir, se vuelve a tomar una decisión y así sucesivamente. Por lo que para alcanzar la solución de este problema o subproblema debemos aplicar prácticamente un árbol de decisión.
Tipos de estructuras repetitivas
En forma indistinta se utiliza estructuras repetitivas, estructura iterativa o bucle para referirse a la repetición de un proceso un número fijo o variable de veces.
En el desarrollo de los procesos iterativos se distinguen los siguientes tipos de bucles.
- Bucles variable:
- Estructura Repetir Hasta que
- Estructura Mientras Hacer
- Bucles fijos
- Estructura Para
Toda estructura repetitiva tiene las siguientes partes.
- Inicialización, en la cual se asigna valores iníciales a las variables que intervienen en el test de salida.
- Actualización, en la que se actualizan las variables que intervienen en el test de salida.
- Instrucción de proceso, parte del bucle en el que se escriben las instrucciones que se deben repetir.
- Test de salida, es la que se controla si el bucle continua o se sale del bucle.
Bucles variables
Son estructuras repetitivas en las que no se conoce el número de veces que se ejecutarán las instrucciones que se encuentran dentro del bucle. Por ejemplo, si se trata se contar el numero de dígitos de un número entero positivo no sabemos cuántos dígitos tendrá el número; consiguientemente no se sabe cuantas veces se realizara el proceso de contar. Otro ejemplo es el número de clientes que debe atender un cajero de banco, quien no sabe a priori cuantas personas existen e cola para ser atendidos.
Bucles fijos
Son estructuras repetitivas en que se conoce a priori el número de veces que se ejecutaran las instrucciones que se encentran dentro del bucle. Ejemplo si se trata de ingresar 5 notas a priori se sabe que se debe leer repetidamente 5 notas; consiguientemente el proceso de leer se repetirá 5 veces.
pseudocodigo,y diagrama de flujo
Antes de entrar de lleno en el establecimiento del significado del término pseudocódigo, se hace necesario que procedamos a determinar el origen etimológico de las dos palabras que le dan forma:
-Pseudo deriva del griego, de “seudo”, que puede traducirse como “falso”.
-Código, por su parte, emana del latín. En concreto, de “codices, codex” que se empleaban para referirse a los documentos o libros donde los romanos tenían escritas todas y cada una de sus leyes.Nuestra lengua apela a diversos elementos compositivos para formar palabras. Uno de los más habituales es pseudo o seudo, que permite referirse a que algo no es original, sino que es falso o una imitación.

-Pseudo deriva del griego, de “seudo”, que puede traducirse como “falso”.
-Código, por su parte, emana del latín. En concreto, de “codices, codex” que se empleaban para referirse a los documentos o libros donde los romanos tenían escritas todas y cada una de sus leyes.Nuestra lengua apela a diversos elementos compositivos para formar palabras. Uno de los más habituales es pseudo o seudo, que permite referirse a que algo no es original, sino que es falso o una imitación.
Un código, por su parte, es una serie de símbolos que forman parte de un sistema y que tienen un determinado valor ya asignado. Los símbolos que se incluyen en un código se combinan respetando reglas y permiten transmitir un mensaje.
El pseudocódigo, en este sentido, esta considerado como una descripción de un algoritmo que resulta independiente de otros lenguajes de programación. Para que una persona pueda leer e interpretar el código en cuestión, se excluyen diversos datos que no son clave para su entendimiento.
Un pseudocódigo, por lo tanto, se emplea cuando se pretende describir un algoritmo sin la necesidad de difundir cuáles son sus principios básicos. De esta manera, un ser humano encontrará mayores facilidades para comprender el mensaje, a diferencia de lo que ocurriría si estuviese frente a un lenguaje de programación real.
A la hora de llevar a cabo la creación de un pseudocódigo, se hace necesario que su estructura se encuentre compuesta de las siguientes partes:
-Una cabecera, que, a su vez, se debe componer de cinco áreas diferenciadas como son el programa, el módulo, los tipos de datos, las constantes y las variables.
-El cuerpo, que se dividirá en inicio, instrucciones y fin.
-Una cabecera, que, a su vez, se debe componer de cinco áreas diferenciadas como son el programa, el módulo, los tipos de datos, las constantes y las variables.
-El cuerpo, que se dividirá en inicio, instrucciones y fin.
Además de todo lo expuesto, se hace importante establecer otra serie de datos de interés relativos a cualquier pseudocódigo:
-Se debe poder ejecutar en cualquier ordenador.
-No tiene nada que ver con el lenguaje de programación que se vaya a poder usar después, es decir, que es independiente respecto al mismo.
-Tiene que ser sencillo de usar y también de manipular.
-Debe permitir que se pueda acometer la descripciones de diversos tipos de instrucciones, tales como de proceso, de control, de descripción, primitivas o compuestas.
-A la hora de poder desarrollar la creación del citado pseudocódigo hay que tener en cuenta que se utilizarán diversos tipos de estructuras de control. En concreto, estas podemos decir que son de tres clases: selectivas, secuenciales e iterativas.
-Se debe poder ejecutar en cualquier ordenador.
-No tiene nada que ver con el lenguaje de programación que se vaya a poder usar después, es decir, que es independiente respecto al mismo.
-Tiene que ser sencillo de usar y también de manipular.
-Debe permitir que se pueda acometer la descripciones de diversos tipos de instrucciones, tales como de proceso, de control, de descripción, primitivas o compuestas.
-A la hora de poder desarrollar la creación del citado pseudocódigo hay que tener en cuenta que se utilizarán diversos tipos de estructuras de control. En concreto, estas podemos decir que son de tres clases: selectivas, secuenciales e iterativas.

diagrama de flujo
Un diagrama de flujo es la representación gráfica del flujo o secuencia de rutinas simples. Tiene la ventaja de indicar la secuencia del proceso en cuestión, las unidades involucradas y los responsables de su ejecución, es decir , viene a ser la representación simbólica o pictórica de un procedimiento administrativo.
Luego, un diagrama de flujo es una representación gráfica que desglosa un proceso en cualquier tipo de actividad a desarrollarse tanto en empresas industriales o de servicios y en sus departamentos, secciones u áreas de su estructura organizativa.
Son de gran importancia ya que ayudan a designar cualquier representación gráfica de un procedimiento o parte de este. En la actualidad los diagramas de flujo son considerados en la mayoría de las empresas como uno de los principales instrumentos en la realizacion de cualquier método o sistema.
A continuación se incluyen dos representación power point , del procedimiento para organizar el evento de una boda, como ejemplo practico de la utilización de los diagramas de flujo en cualquier proceso o actividad.

Luego, un diagrama de flujo es una representación gráfica que desglosa un proceso en cualquier tipo de actividad a desarrollarse tanto en empresas industriales o de servicios y en sus departamentos, secciones u áreas de su estructura organizativa.
Son de gran importancia ya que ayudan a designar cualquier representación gráfica de un procedimiento o parte de este. En la actualidad los diagramas de flujo son considerados en la mayoría de las empresas como uno de los principales instrumentos en la realizacion de cualquier método o sistema.
A continuación se incluyen dos representación power point , del procedimiento para organizar el evento de una boda, como ejemplo practico de la utilización de los diagramas de flujo en cualquier proceso o actividad.

Suscribirse a:
Comentarios (Atom)